




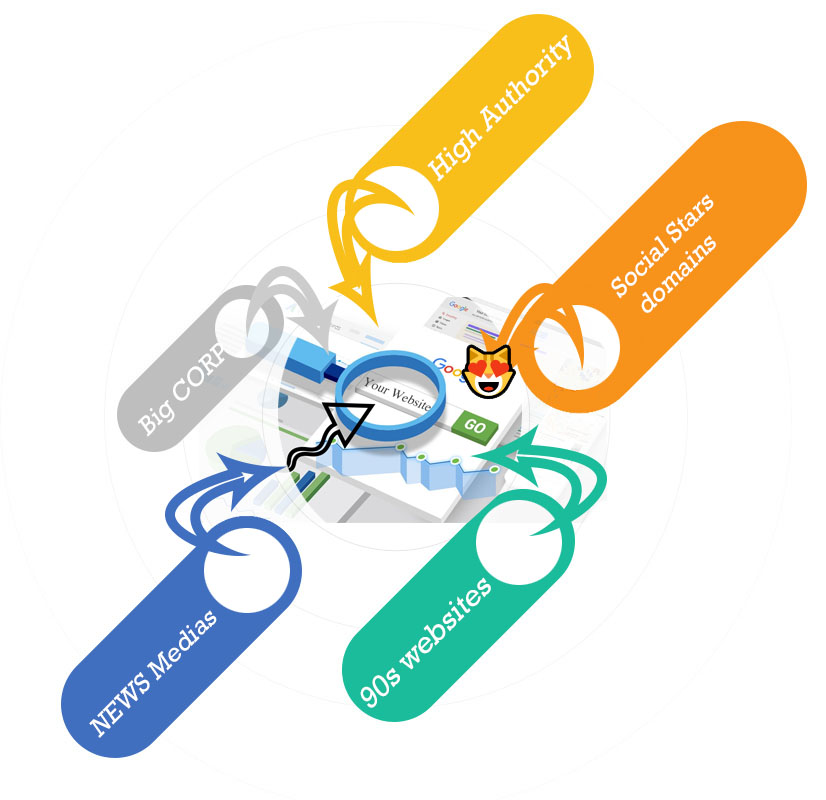
Find expired domains with reputation that have backlings from high power websites.
Would you like to have a backlink from sites like CNN.COM ?
Boost massively your Google ranking, build your own PBN network with expired domains.
Best Domain Crawler
Big Expire Domain Database
We give you the tool, that is built around the methodology that we and SEO experts use to skyrocket SERP rankings. It is all about Domain Authority, how much quality backlinks you have and how relevant are they.
"THE DATA DIGGER" will find the expired domains that are relevant for your business niche, crawling high authority websites (no matter how huge they are), rank them by backlinks and check them for availability.
You will be granted access to Huge Database of Expired Domains, crawled from nodes all around the world. "THE DATA DIGGER" is distributed software which have its own pool of big data. Join the matrix.
Profit from selling digital information
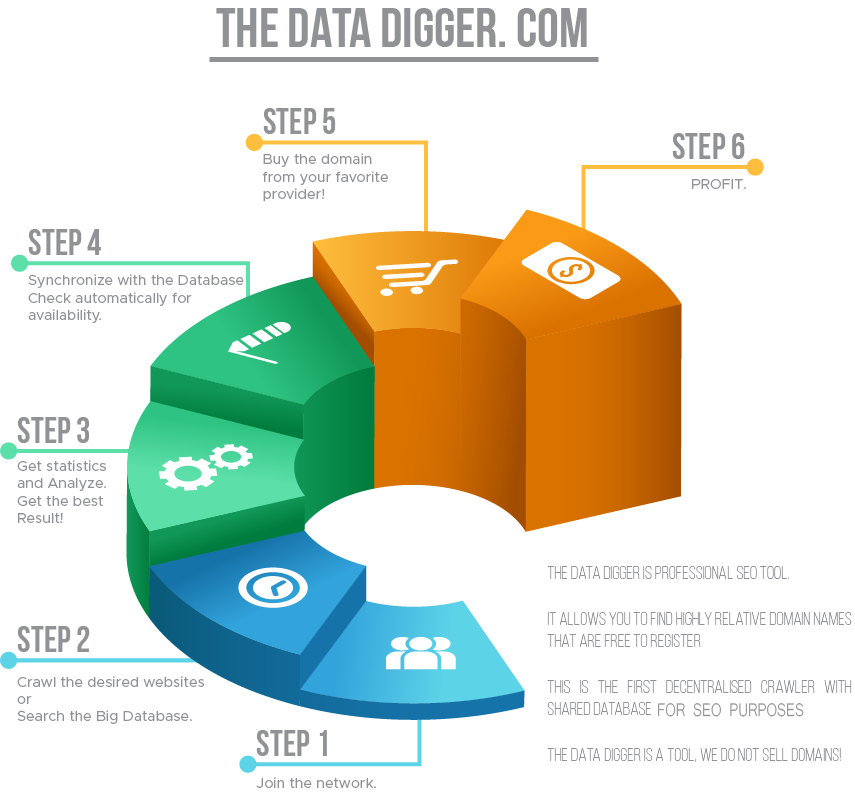
How to use
"The Data Digger"
to profit
All data generated through our tool is there to help you profit.
Ways to directly cashout:
- Redirect the domain to your website and gain instant positions in search engines.
- Create your own PBN network and boost your or client's websites.
- Establish a business on the domain you found. Turnkey SEO.
- Flip the domain on marketplaces like Flippa.com.
- Start selling high quality links from the domains you find.
- Park your domain and earn from advertisment.

increase of approximately 6.0 million domain name registrations, or 1.8 percent, compared to the first quarter of 2018
2018 closed with approximately 339.8 million domain name registrations
 * statistics source VeriSign
* statistics source VeriSign

Join the nework
Get access to the professional SEO tool
Find a plan that's right for you.
-

Subscription
$ 30 Month
Get Started Now -

One Time
$ 160
Get Started Now -
Data Masters
$ASK
Ask for price

Let's Get Digging
12 PULLMAN GARDENS, LONDON
![]()
![]()
![]()
Email: main101 |'@'| thedatadigger.com